这篇文章记录一个很小的可视化实验:用同一份 MNIST 数据、同样的二维 latent,分别训练 AE、VAE 和 VQ-VAE,然后把每个 epoch 的 latent 空间画成 GIF。
我想看的不是哪个模型重建得最好,而是一个更基础的问题:
- 不加正则时,encoder 会把图片压到什么样的二维空间?
- 加
KL正则后,latent 为什么会更连续、更像高斯? - 加
VQ正则后,latent 为什么会被吸到有限个离散原型点附近?
先看总对比:
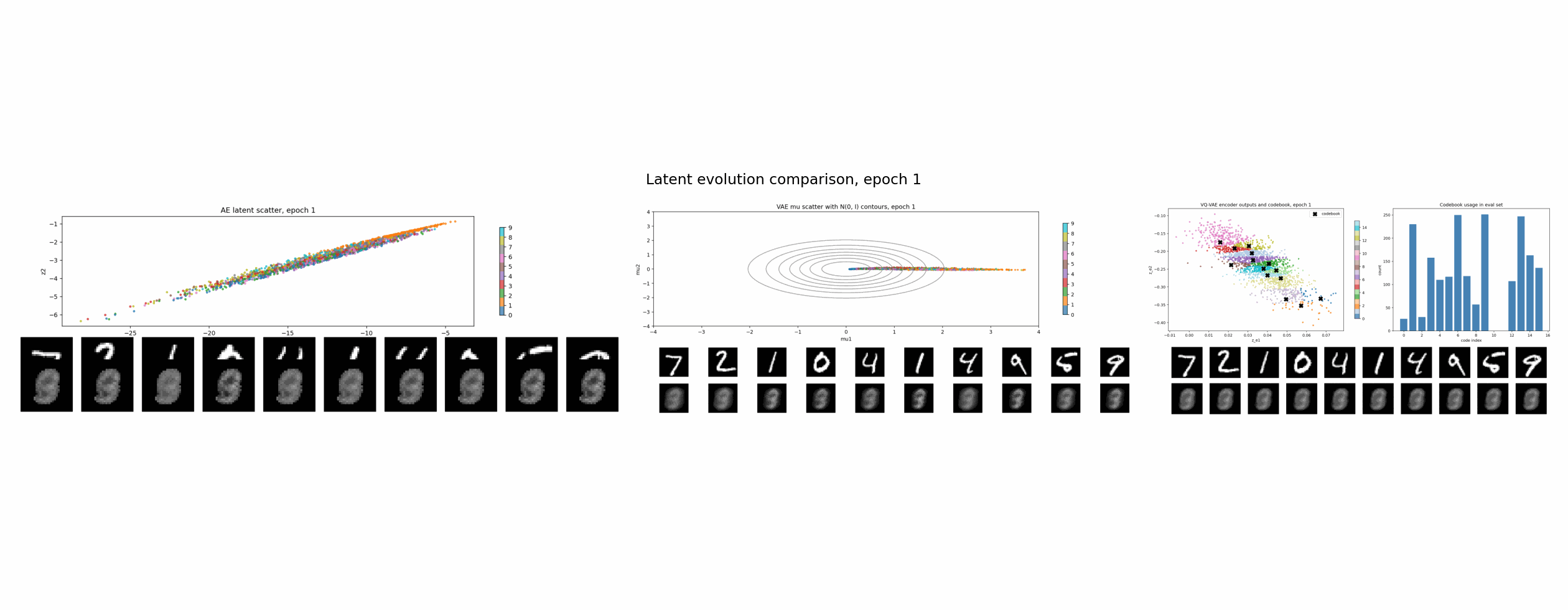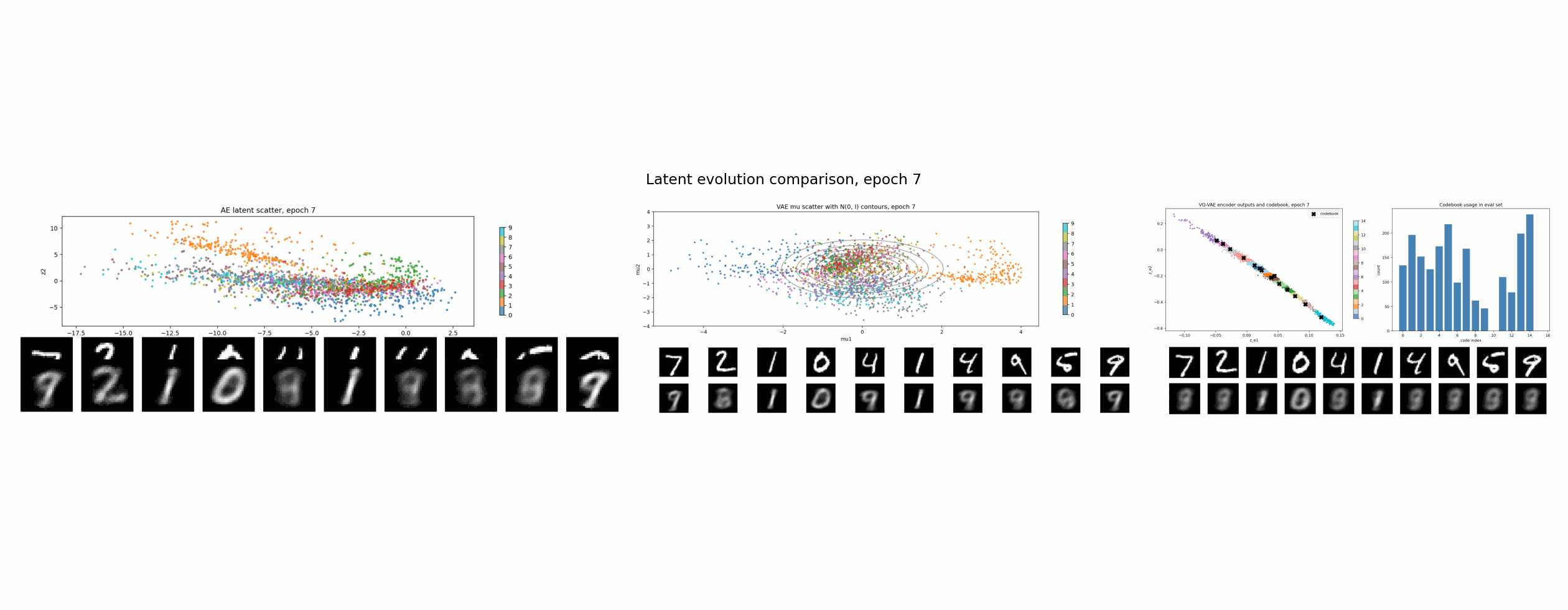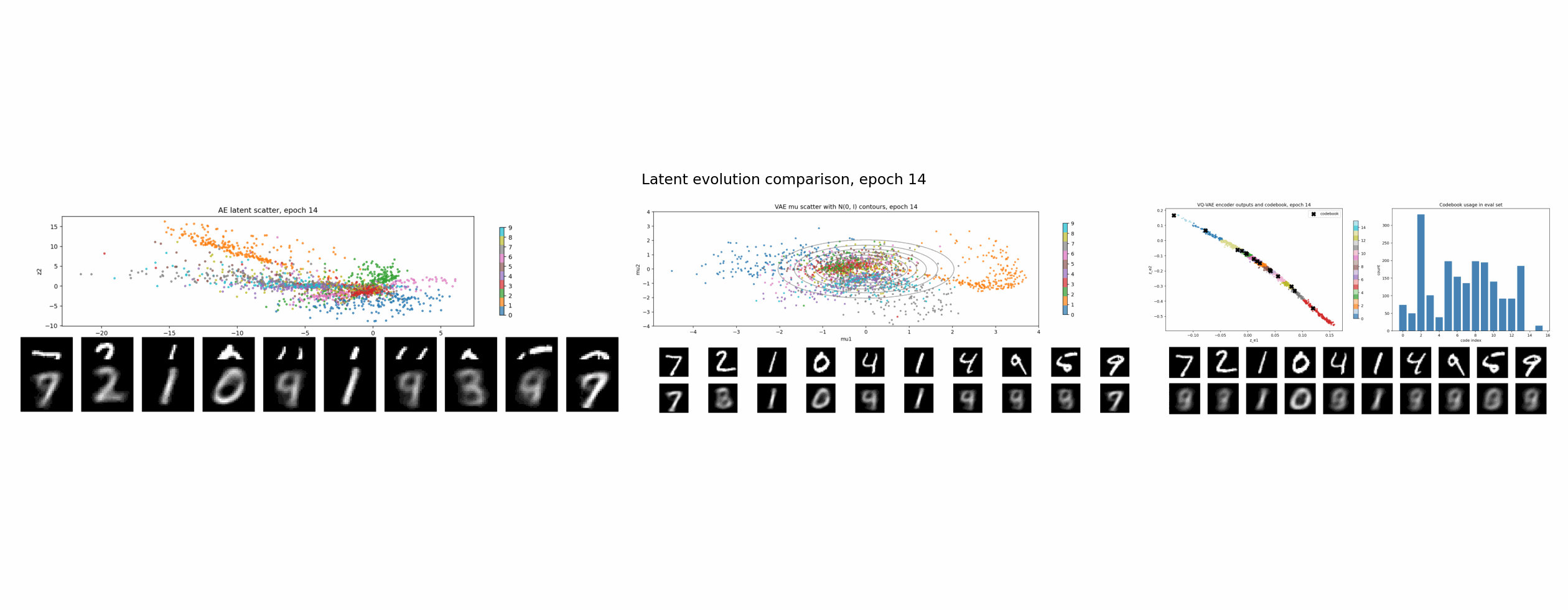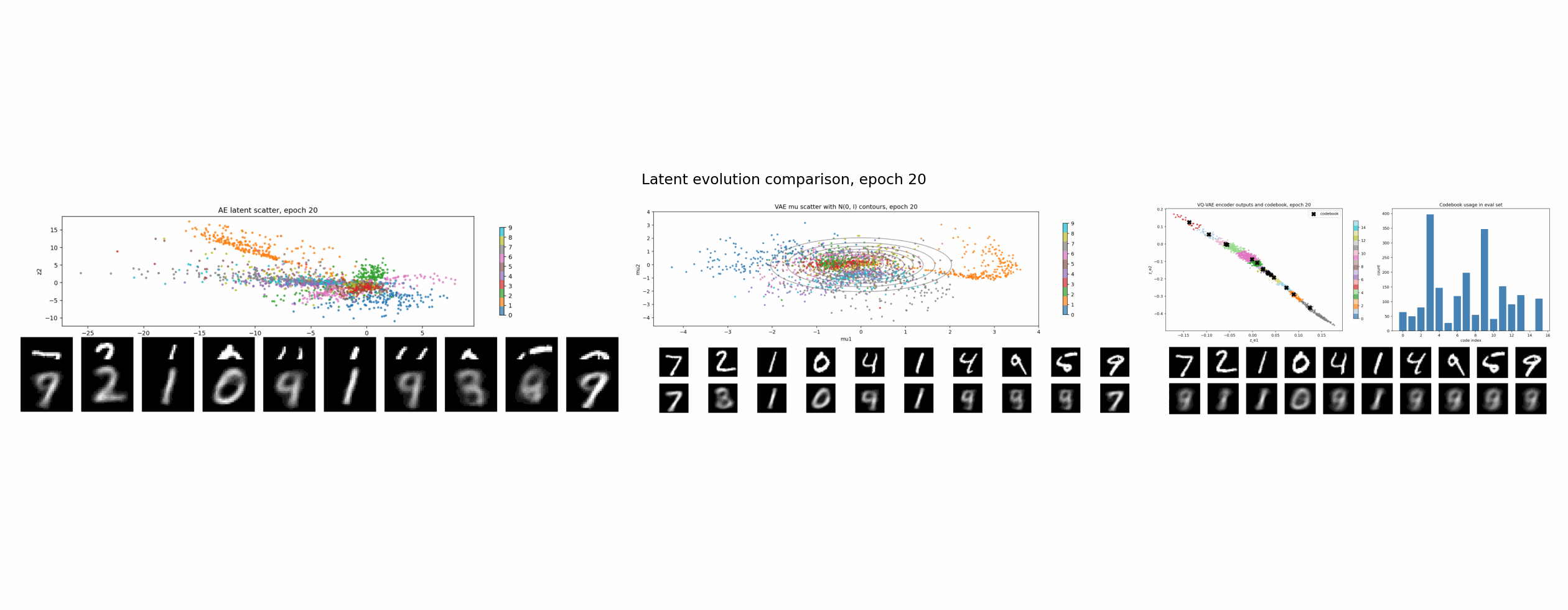
实验设置
所有模型都做同一件事:
x -> z -> x_hat
输入是 28x28 的 MNIST 手写数字图。encoder 把图像压到二维 latent z,decoder 再从 z 还原图像。
我们的设置:
- latent 维度固定为
2,这样可以直接画散点图; - encoder / decoder 都用小 MLP,而不是 CNN;
- 训练集取约
10000张,验证和可视化取约2000张; - 每个 epoch 都画一次同一批样本的 latent。 这个实验不是生成质量 benchmark,而是一个几何直觉实验。模型越简单,越容易看出正则项本身在干什么。
AE:没有 latent 正则
普通 autoencoder 的目标最直接:
L_AE = reconstruction loss
它只关心一件事:从 z 解码回来的 x_hat 像不像原图。
至于 z 长什么样,它没有意见。只要 decoder 能用,latent 可以拉长、弯曲、拥挤,也可以形成一些很不规整的类别岛。
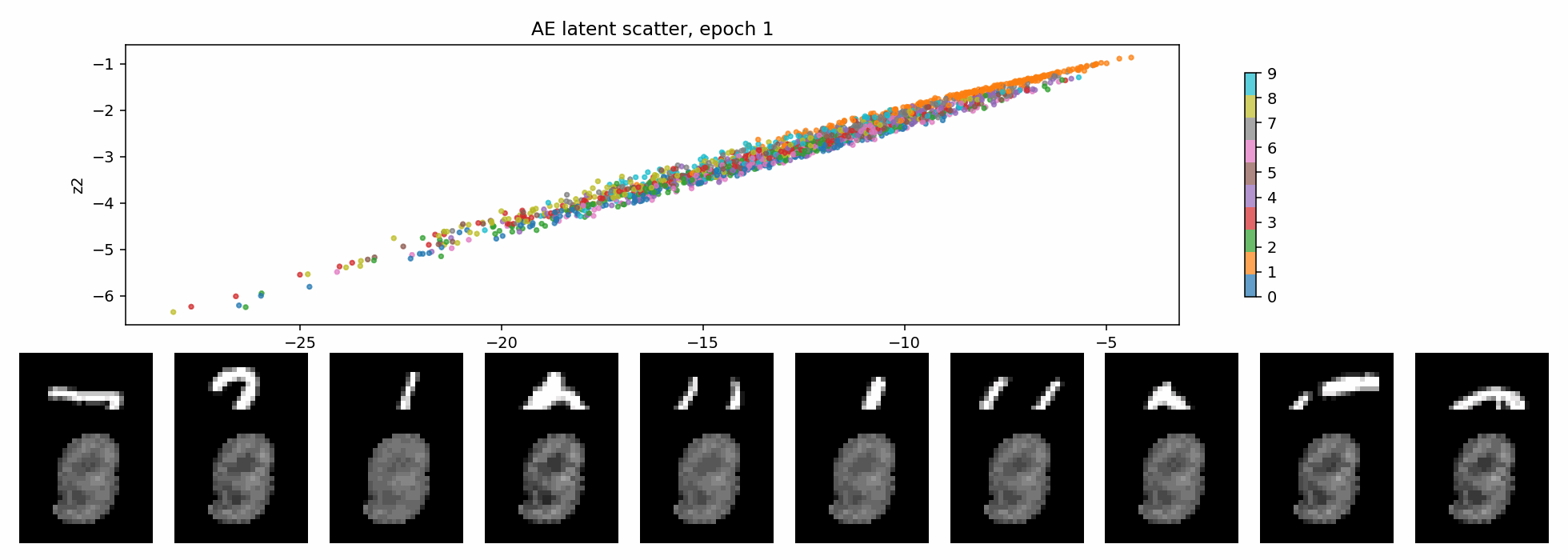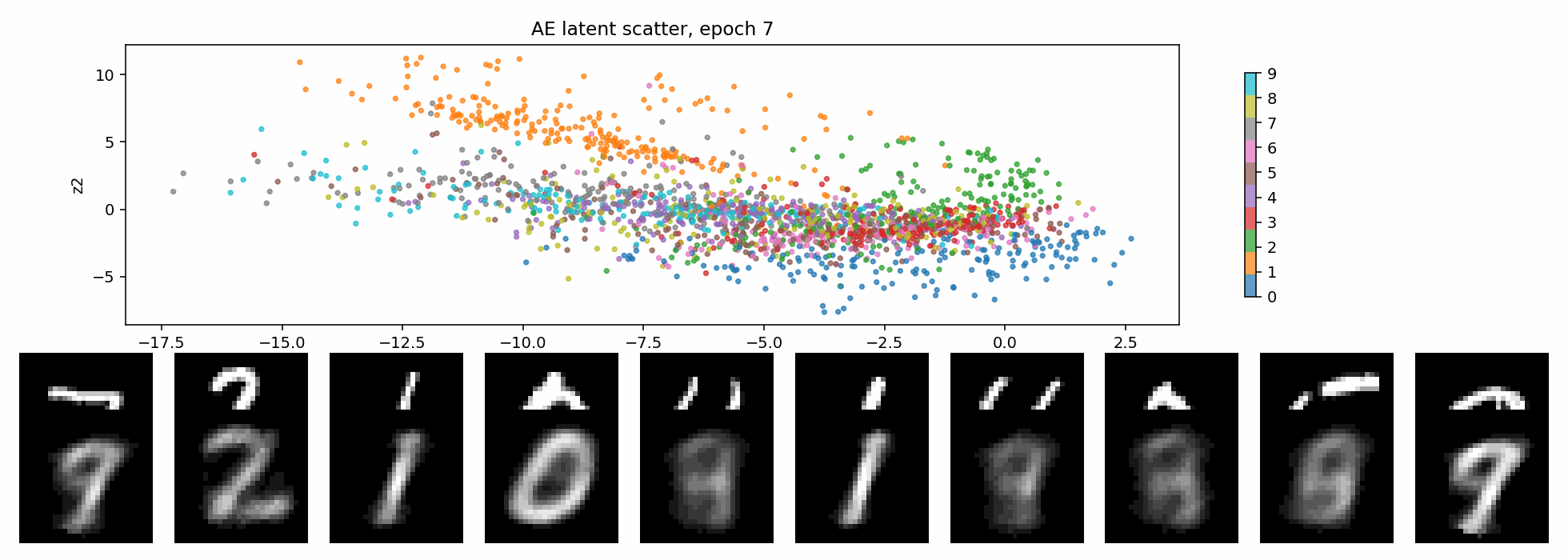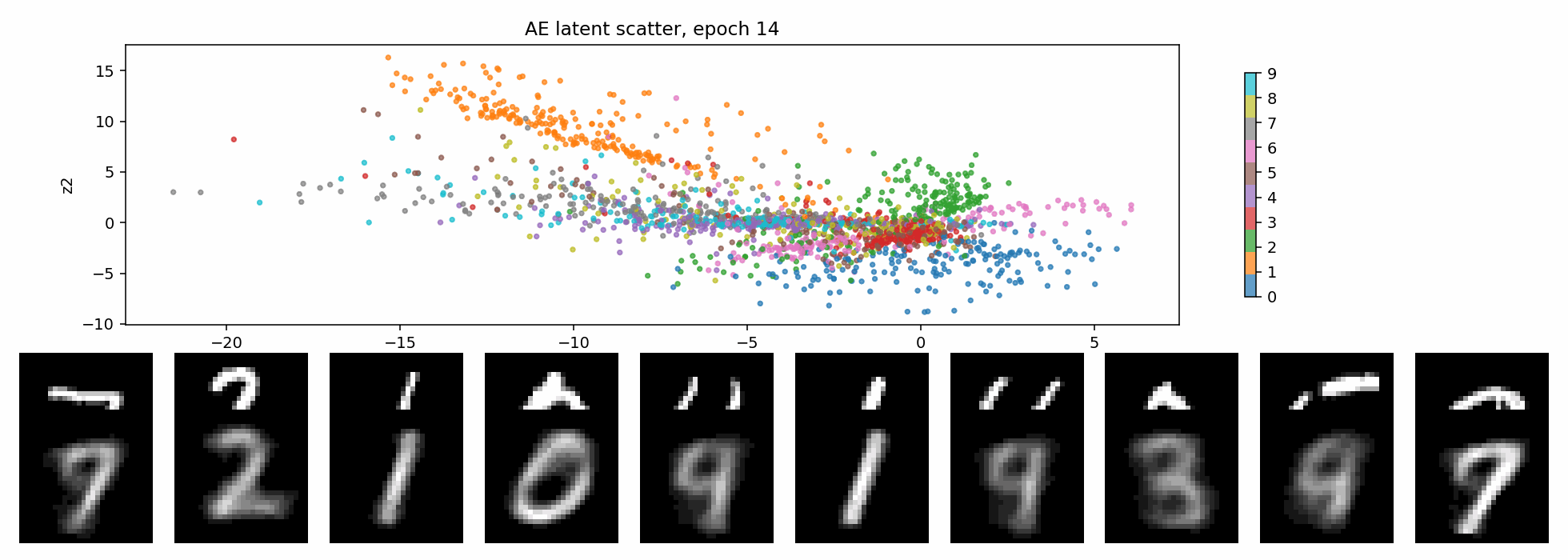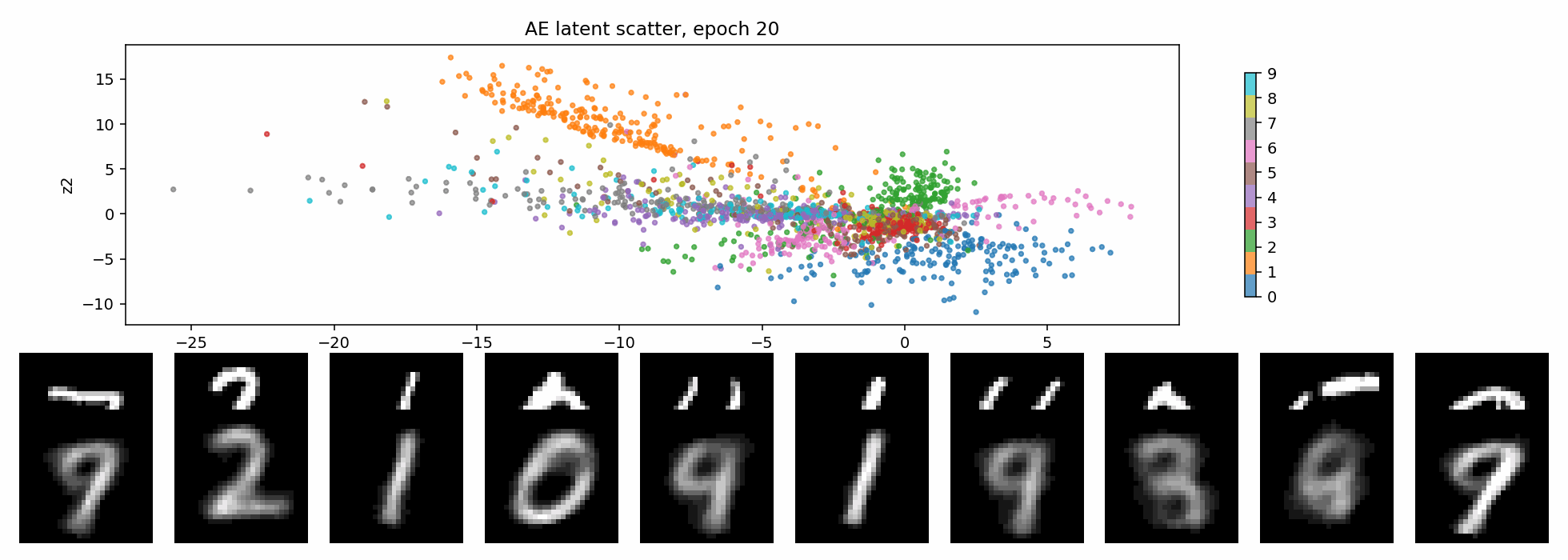
所以 AE 的 latent 可以总结成一句话:
有用,但不一定规整。
这也是为什么直接在 AE latent 上做采样通常很别扭。你不知道哪些地方能解码出合理图片,哪些地方只是 decoder 从没见过的空洞。
VAE:KL 正则把空间整理成连续分布
VAE 和 AE 的关键区别是:encoder 不再直接输出一个点,而是输出一个分布的参数:
q(z | x) = Normal(mu(x), sigma(x)^2)
训练时从这个分布里采样:
z = mu + sigma * epsilon, epsilon ~ Normal(0, I)
loss 里多了一项 KL:
L_VAE = reconstruction loss + beta * KL(q(z | x) || p(z))
其中 p(z) 通常是标准高斯 Normal(0, I)。
KL 项的直觉很简单:encoder 不能把每张图随便扔到任意位置,它输出的分布要被拉回到一个统一的、连续的、接近标准高斯的空间里。
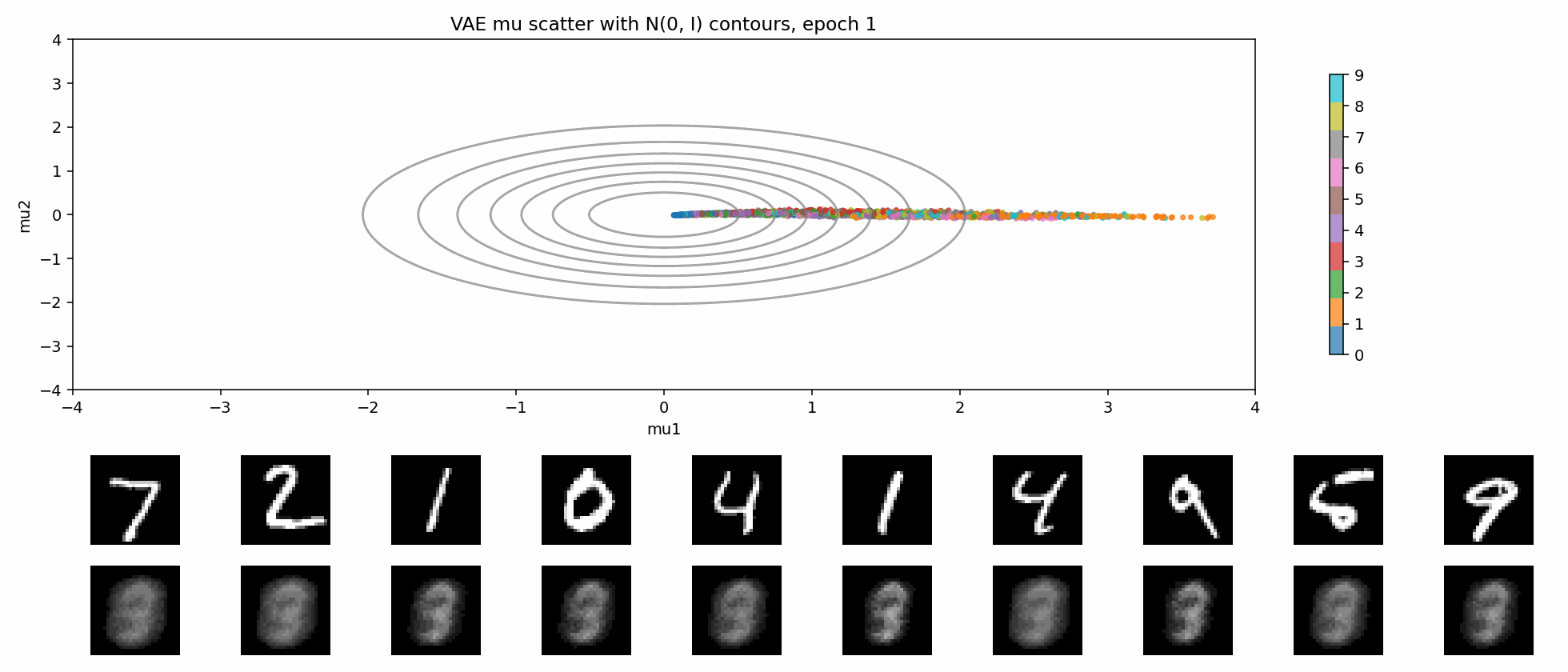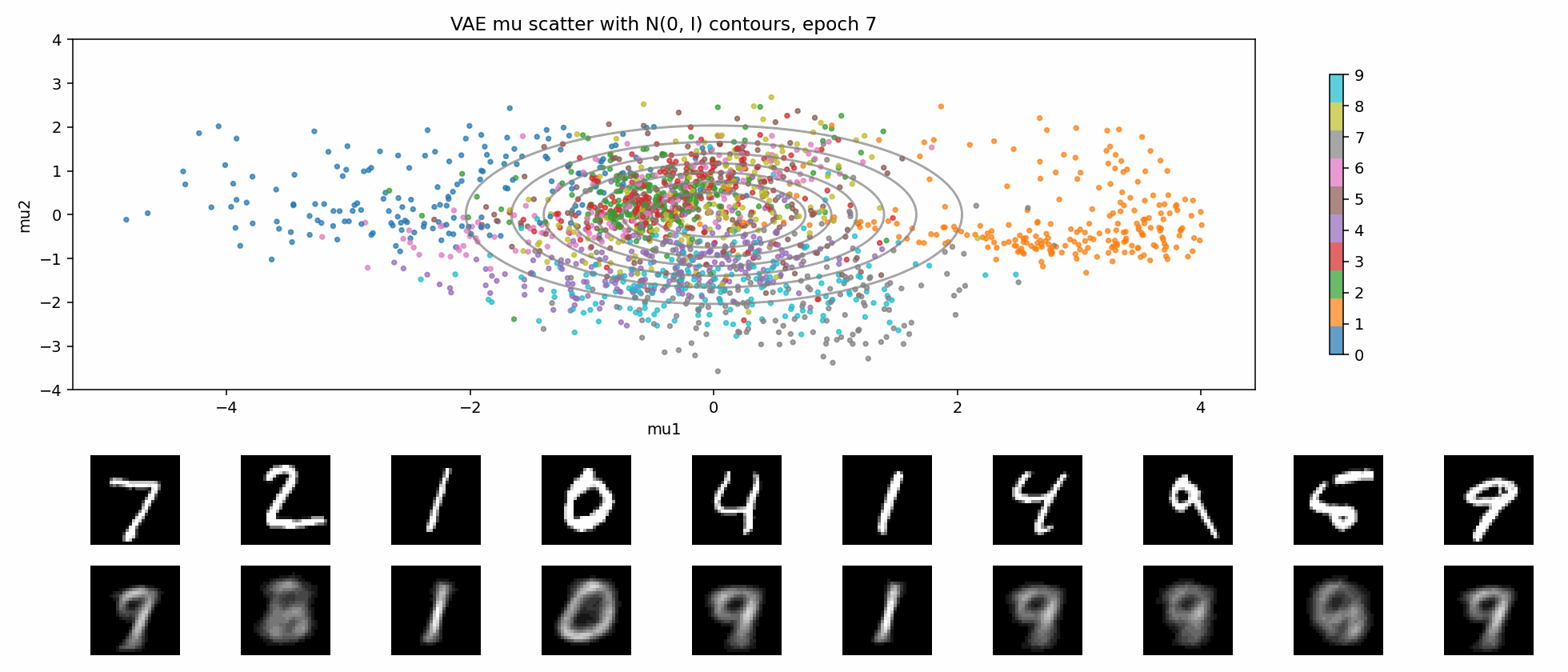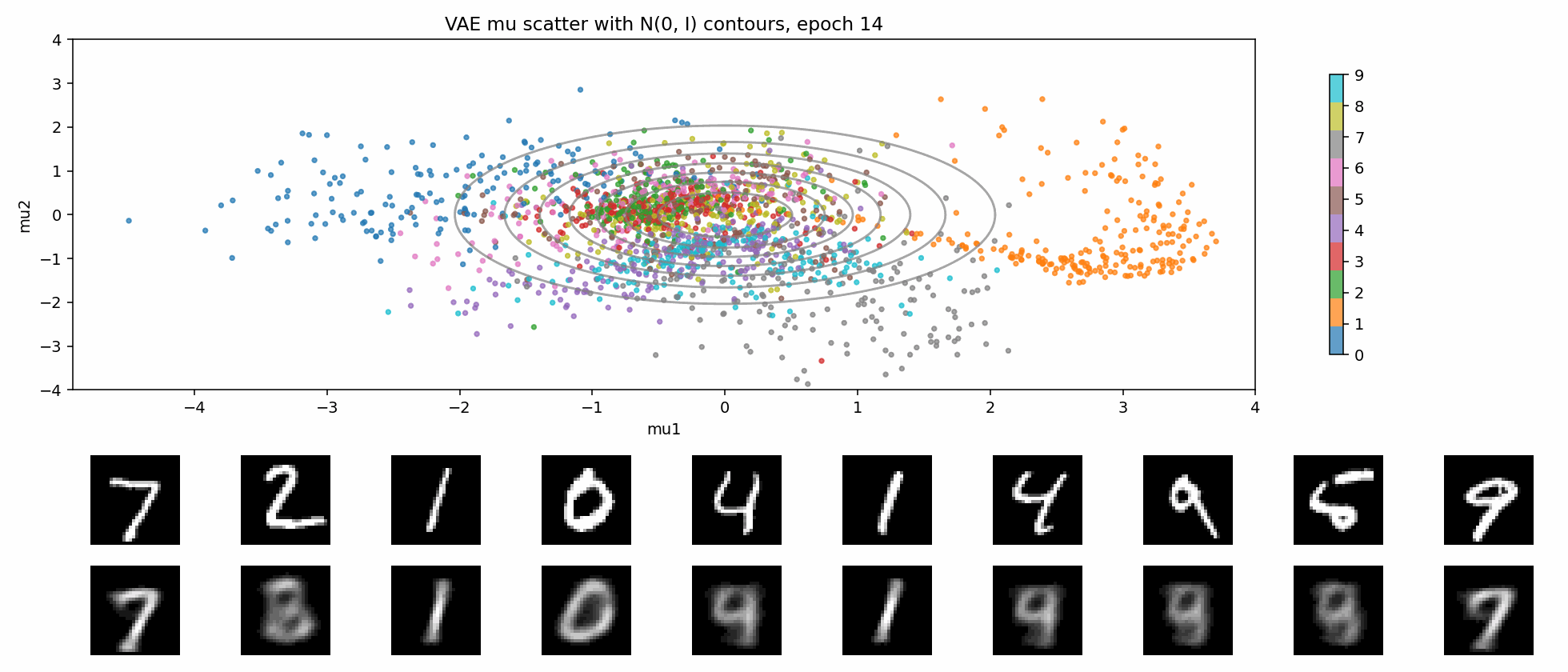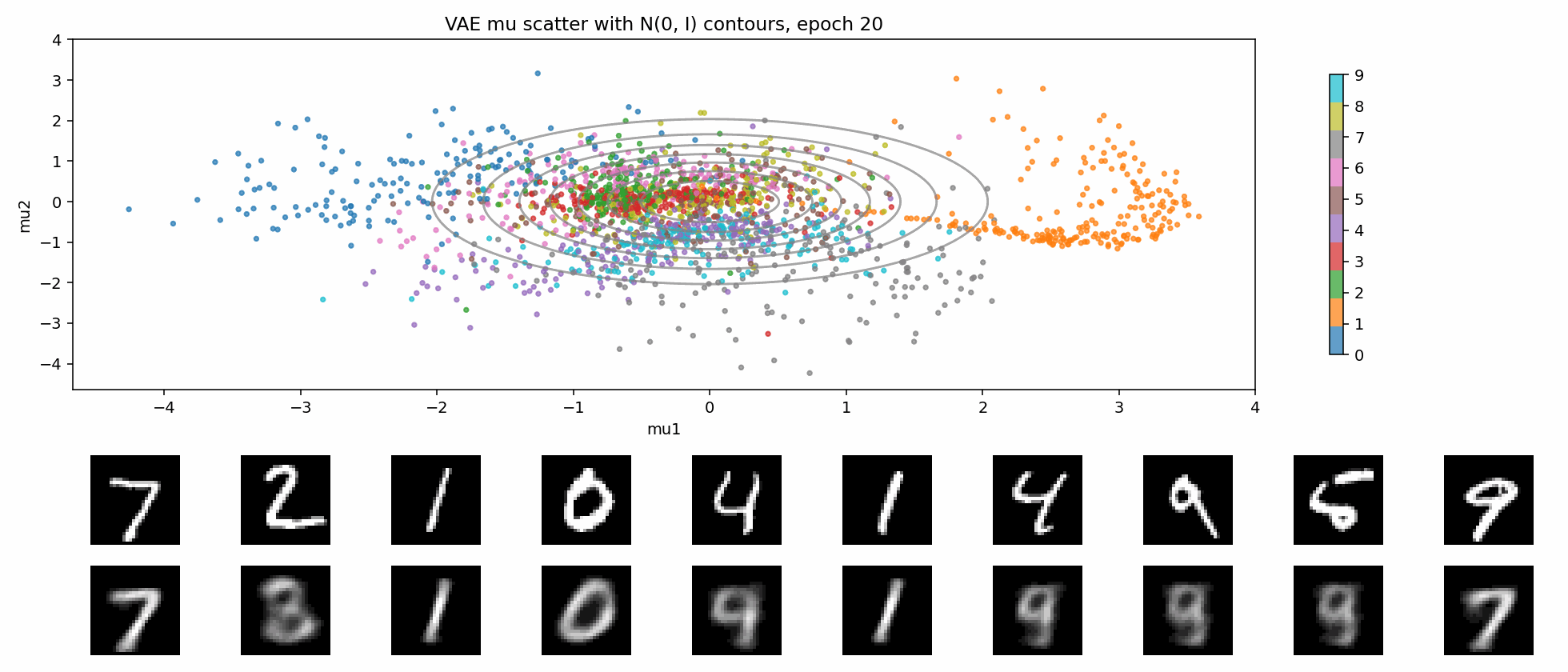
这就是 KL 正则带来的交换:
- 好处:latent 空间更连续,插值和采样更自然;
- 代价:不能把每个样本都随意编码到最方便重建的位置,重建会受到约束;
- 如果 KL 太强,还可能出现 posterior collapse。
下面这个 GIF 更直观:固定一张二维网格,每个 epoch 都把网格点送进 VAE decoder。随着训练推进,这个平面逐渐从噪声变成可解码的生成空间。
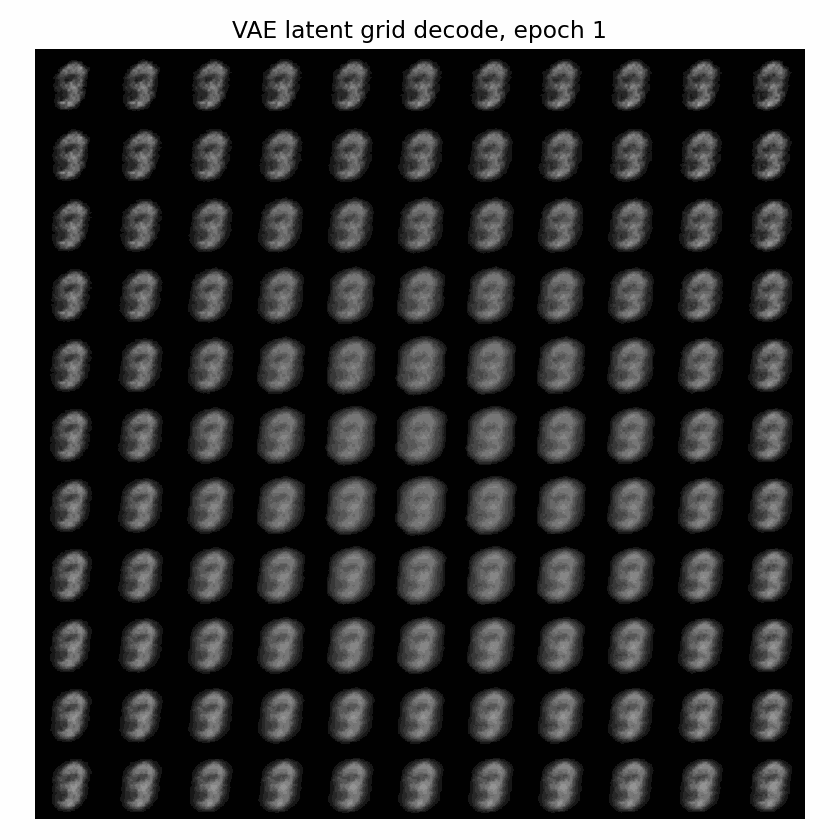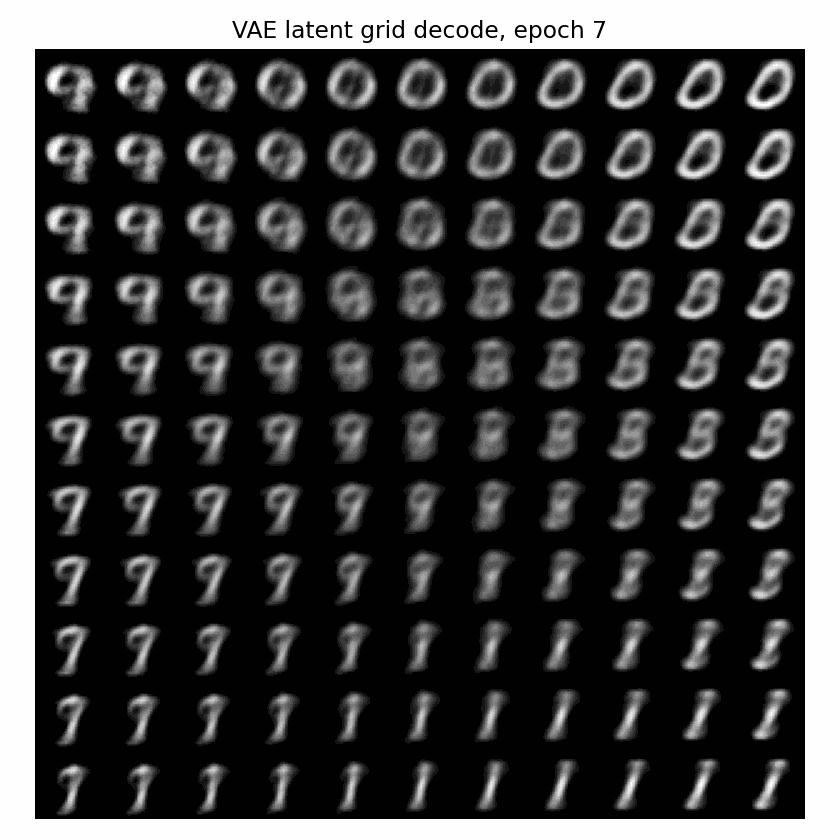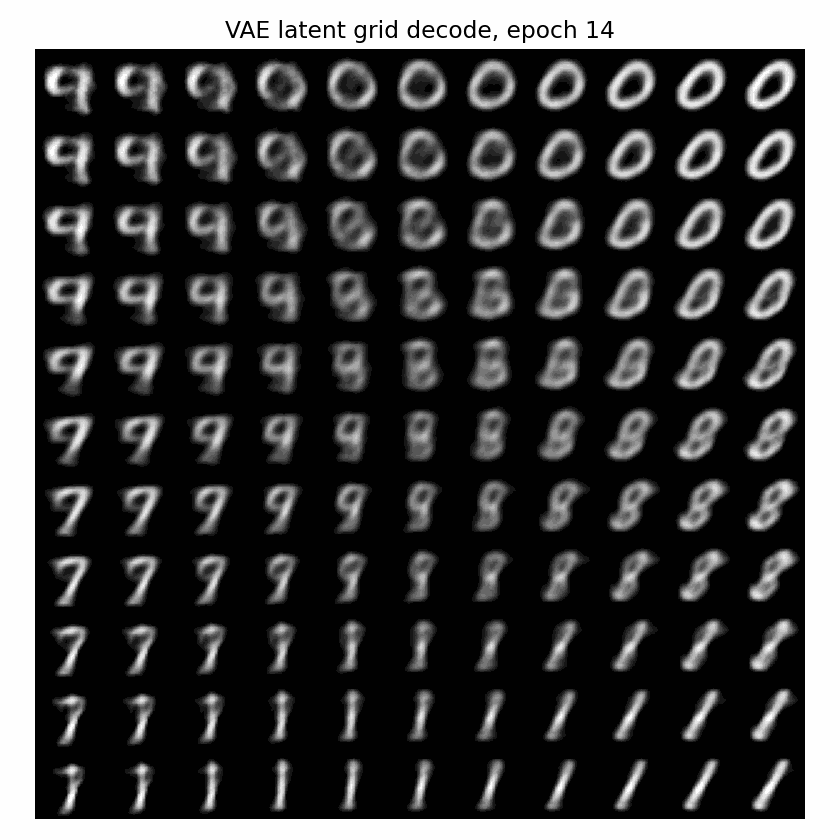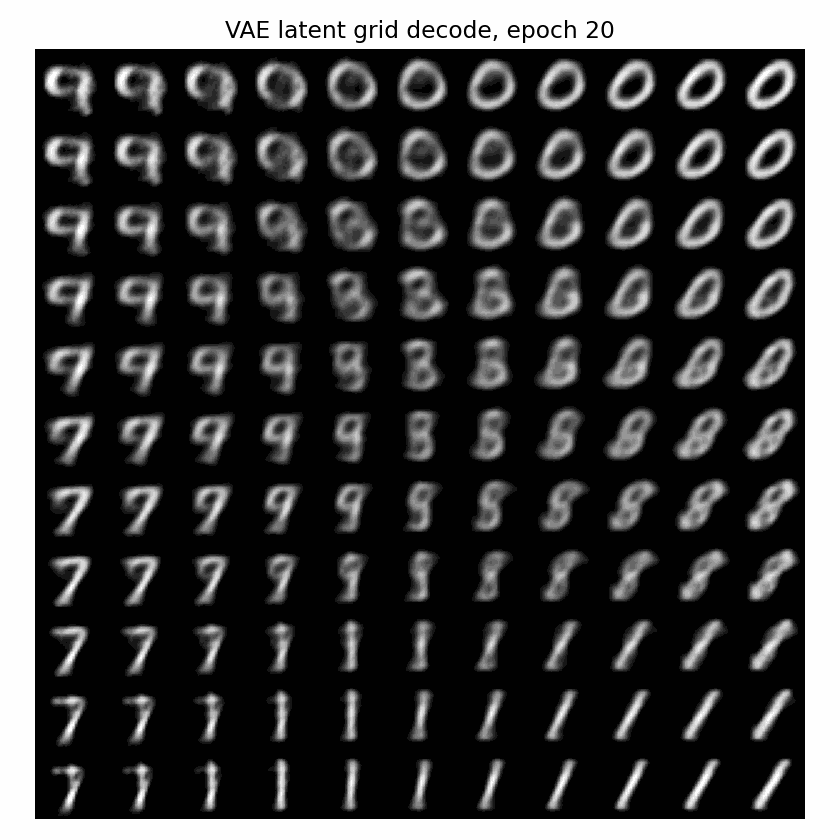
一句话说,KL 正则是在逼 latent 变成:
连续的、可采样的、接近高斯的空间。
VQ-VAE:VQ 正则把空间吸到有限个原型上
VQ-VAE 走的是另一条路线。它不要求 latent 像高斯,而是把 latent 离散化。
流程大概是:
- encoder 输出连续向量
z_e(x); - 准备一个 codebook,里面有
K个可学习向量; - 对每个
z_e(x),找到最近的 codebook 向量; - 用这个最近的 code 替换原来的连续向量,得到
z_q(x); - decoder 用
z_q(x)重建图像。
也就是:
continuous encoder output -> nearest codebook vector -> decoder
在这个实验里,codebook 有 16 个二维向量。图里的黑色 X 是 codebook 原型,彩色点是 encoder 输出。
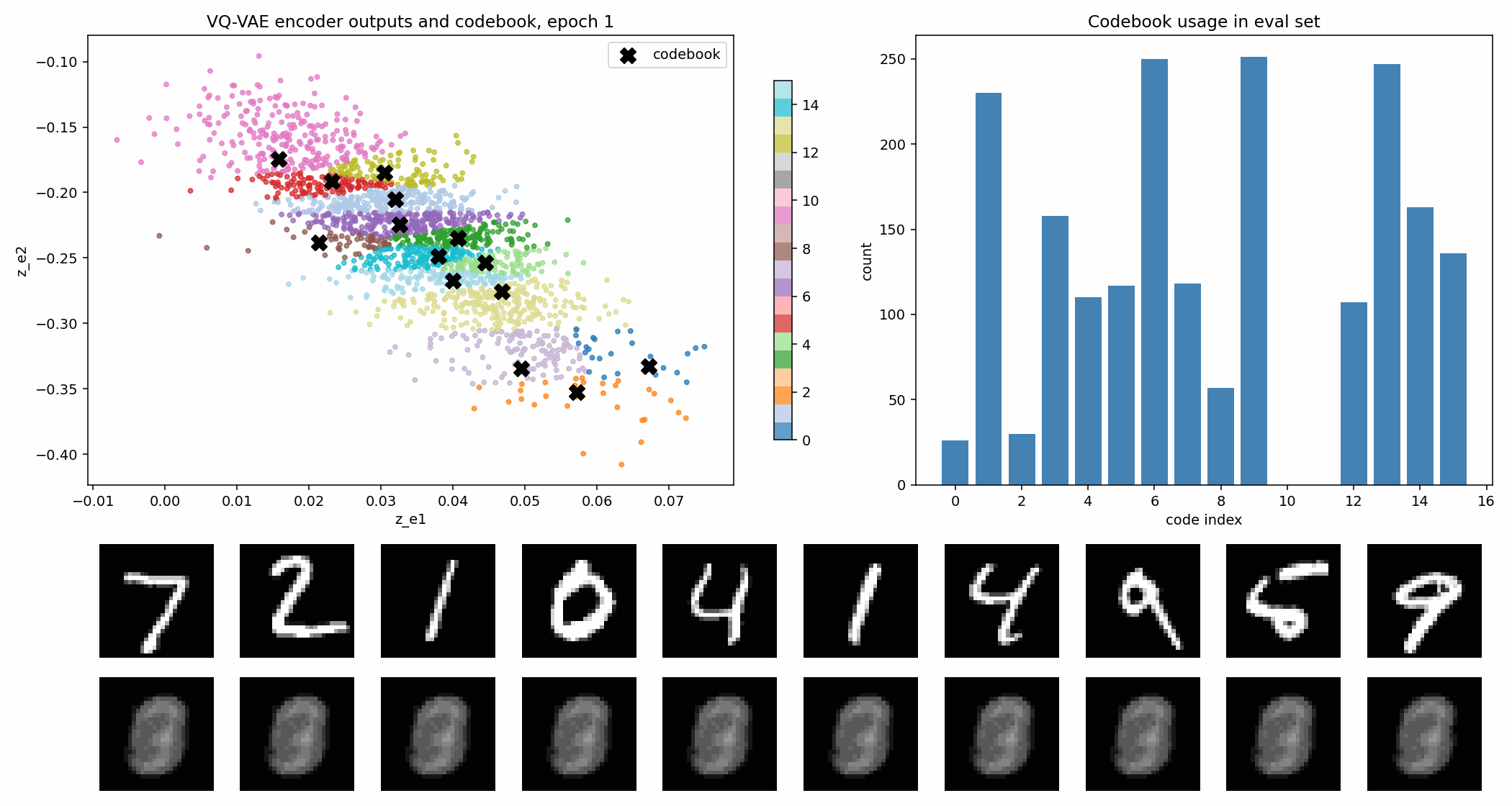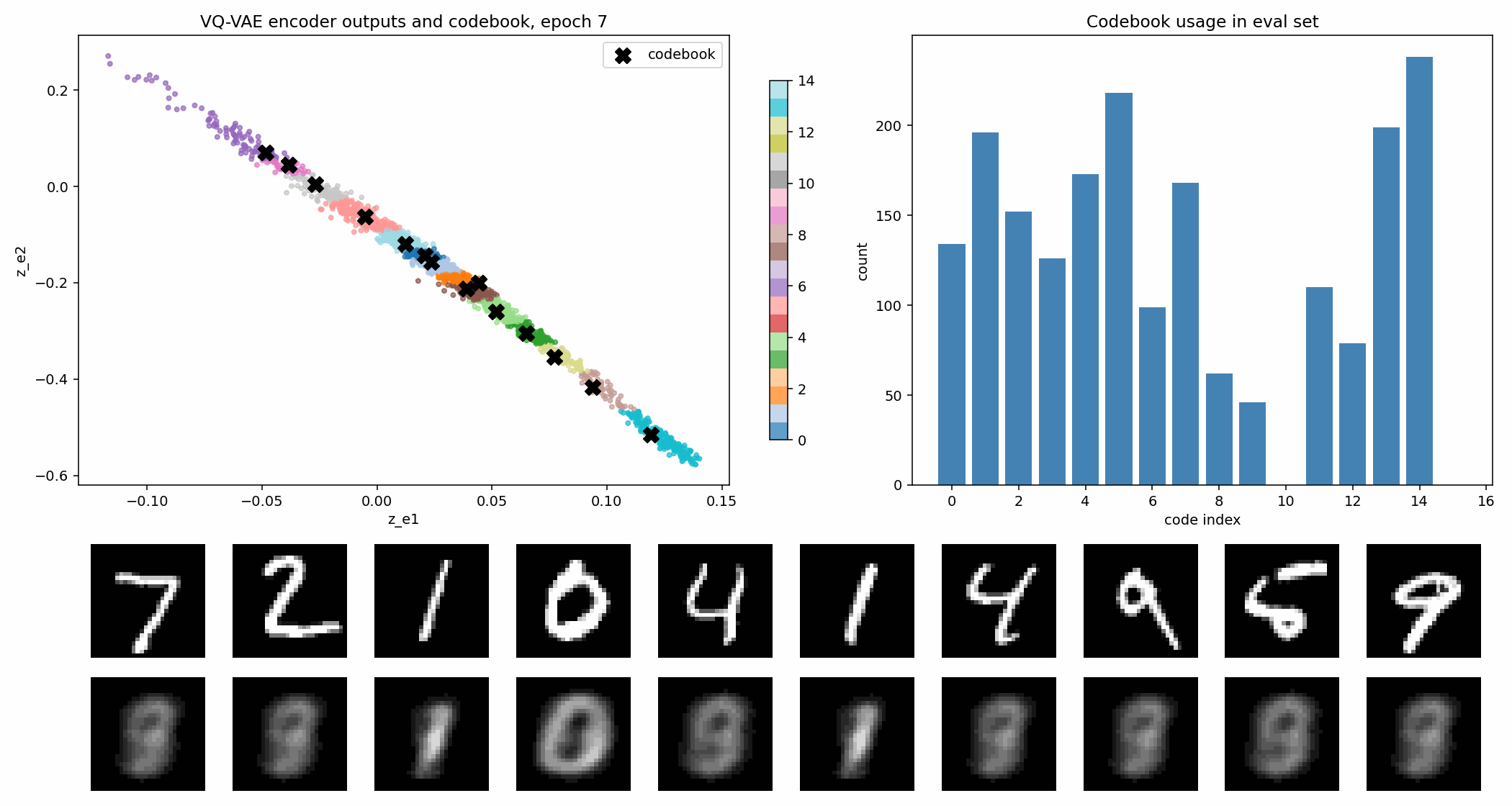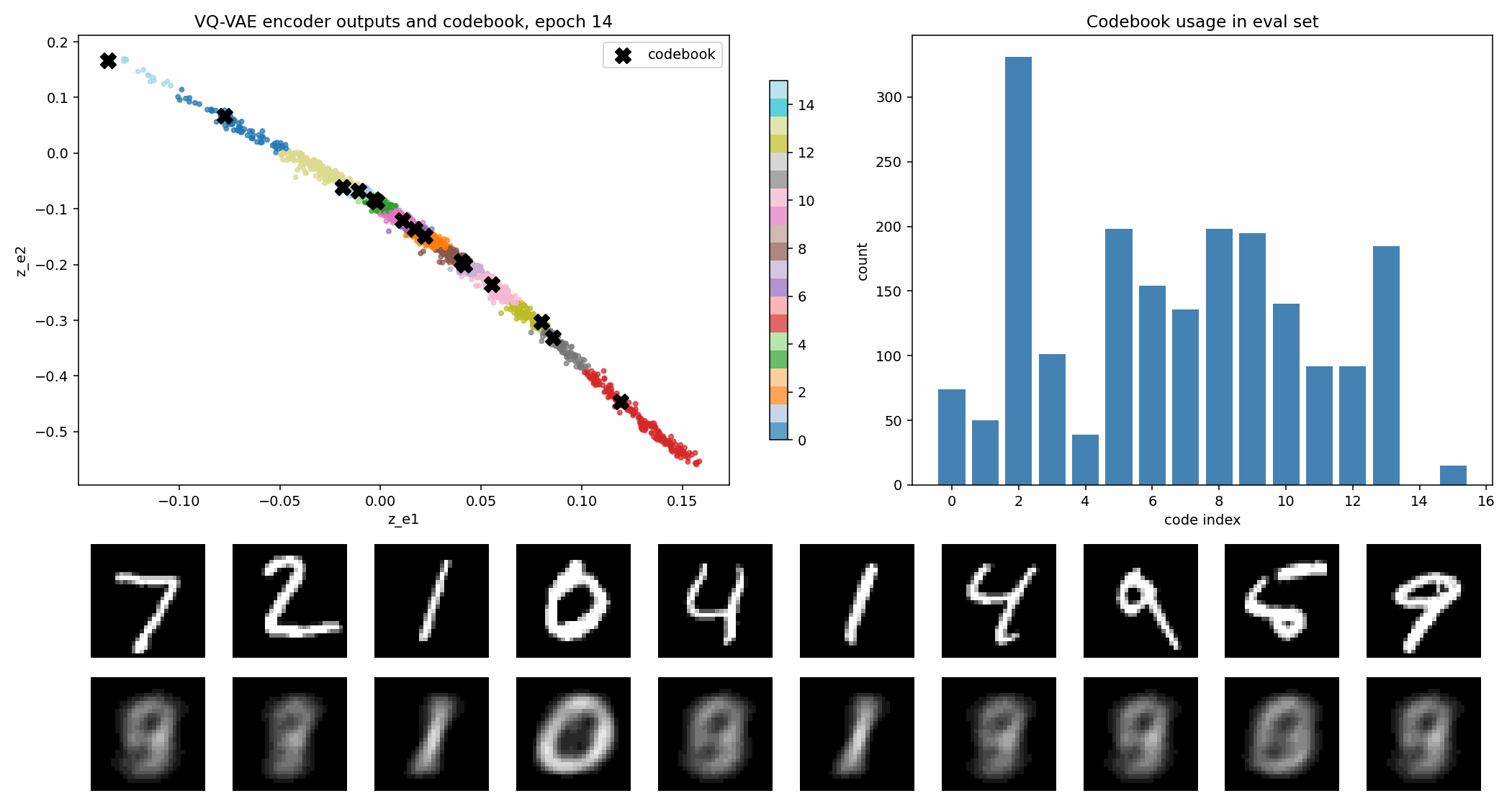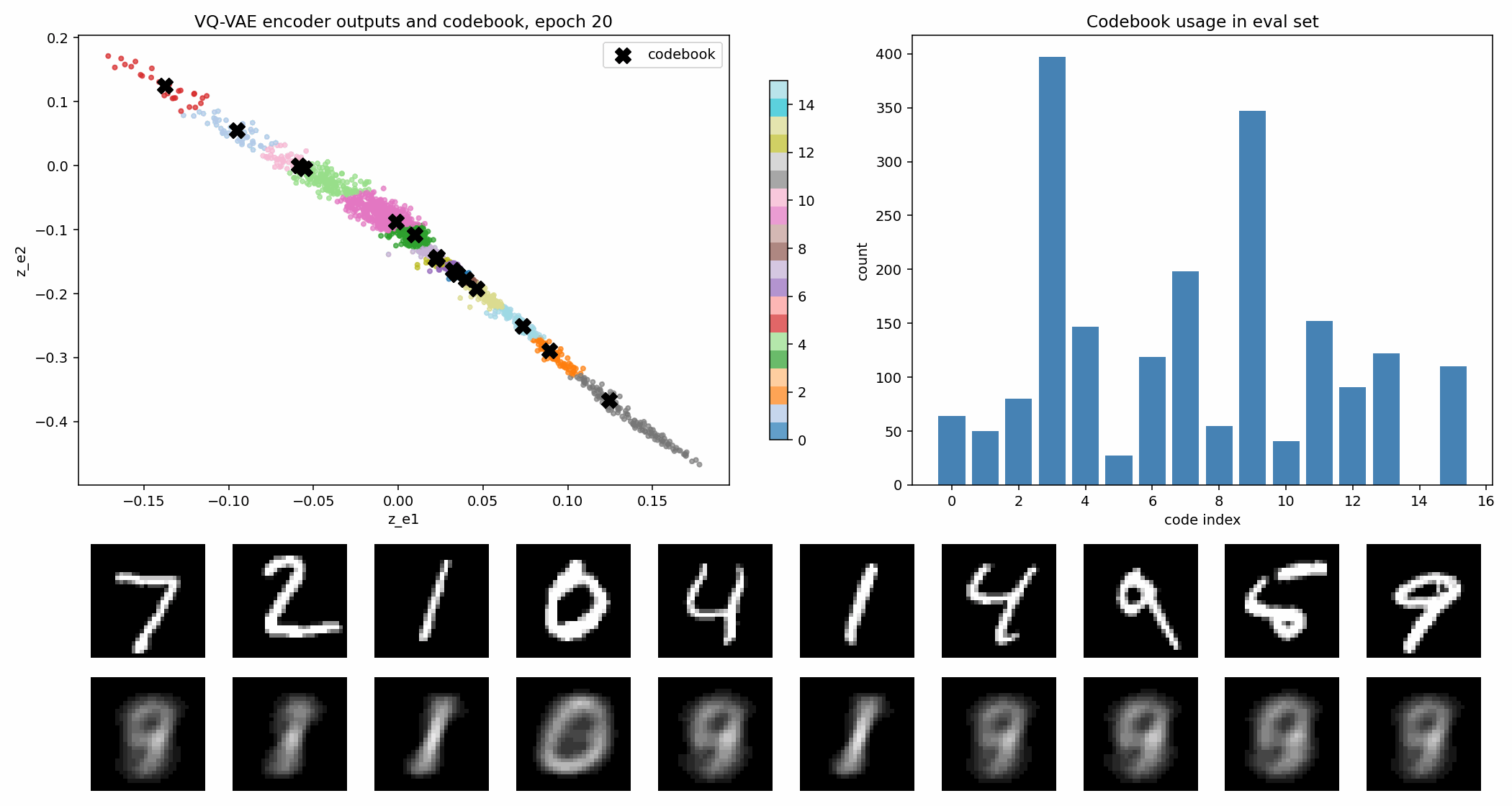
VQ-VAE 的 loss 通常可以理解成三部分:
L_VQ = reconstruction loss + codebook loss + commitment loss
其中最值得建立直觉的是 commitment loss。量化操作会把 encoder 输出硬替换成最近的 codebook 向量,如果不约束 encoder,它可能一直输出离 code 很远的位置,反正最后会被替换掉。commitment loss 的作用就是让 encoder 真的“承诺”靠近它被分配到的 code。
所以 VQ 正则带来的交换是:
- 好处:latent 变成离散 token,更容易接 Transformer 这类序列模型;
- 好处:空间里出现有限原型,结构更像聚类;
- 代价:量化会损失连续细节;
- 训练上需要处理 dead code、codebook 更新稳定性等问题。
一句话说,VQ 正则是在逼 latent 变成:
离散的、原型化的、贴近有限码本的空间。
KL 和 VQ 的核心区别
我觉得可以用这张表记住:
| 模型 | latent 约束 | 空间形状 | 更适合什么 |
|---|---|---|---|
| AE | 无显式约束 | 自由生长,不一定规整 | 重建、压缩 |
| VAE | 分布约束 | 连续、平滑、接近高斯 | 采样、插值、连续生成 |
| VQ-VAE | 离散码本约束 | 聚类、吸附、原型化 | 离散 token、序列建模 |
所以 KL 和 VQ 不是谁替代谁,而是在给 latent 空间施加两种不同的 inductive bias:
KL问的是:能不能把所有样本组织进一个连续、可采样的概率空间?VQ问的是:能不能把样本压到一组有限的、可复用的离散原型上?
为什么这和 latent diffusion 有关
这几个模型本身不是 diffusion,但它们解释了 latent diffusion 里一个很核心的前置问题:为什么要先学一个 latent 空间?
像 Stable Diffusion 这类模型并不直接在像素空间里做完整生成,而是在压缩后的 latent 空间里做去噪。这样做的前提是:encoder 需要把图像压成一个足够小、足够有结构、又不会丢太多语义的信息空间。
而 KL 和 VQ 正则就是塑造这个空间的两种典型方式:
- KL-style autoencoder 倾向于给 diffusion 一个连续 latent;
- VQ-style tokenizer 倾向于给后续模型一串离散 token。
从这个角度看,这个 MNIST 小实验虽然很小,但它展示的是一个会反复出现的大问题:
生成模型不只是学 decoder,也是在设计 latent 空间的几何。
复现实验
这个实验的核心设置如下:
epochs = 20
batch_size = 256
latent_dim = 2
vae_beta = 1.0
vq_num_codes = 16
vq_commitment_beta = 0.25
vq_decay = 0.95
Takeaway
- AE 学的是“够用的压缩表示”;
- VAE 用
KL把 latent 变成连续、规整、接近高斯的空间; - VQ-VAE 用 vector quantization 把 latent 变成贴近有限 codebook 的离散空间。
看懂这三张图之后,再去看 VAE、VQ-VAE、image tokenizer、latent diffusion,会容易很多。